
Our Data Modalities
Purpose-Built Data Infrastructure for AI Teams
Transcription, Recording, annotation, translation, ocr, and custom collection — each modality defined by contractual accuracy thresholds and documented sourcing methodology. Self-qualify your use case below.
Service Pillars
Evaluate Each Modality Against Your Pipeline
99%+ Domain-Specific Accuracy
Expert Data Annotation
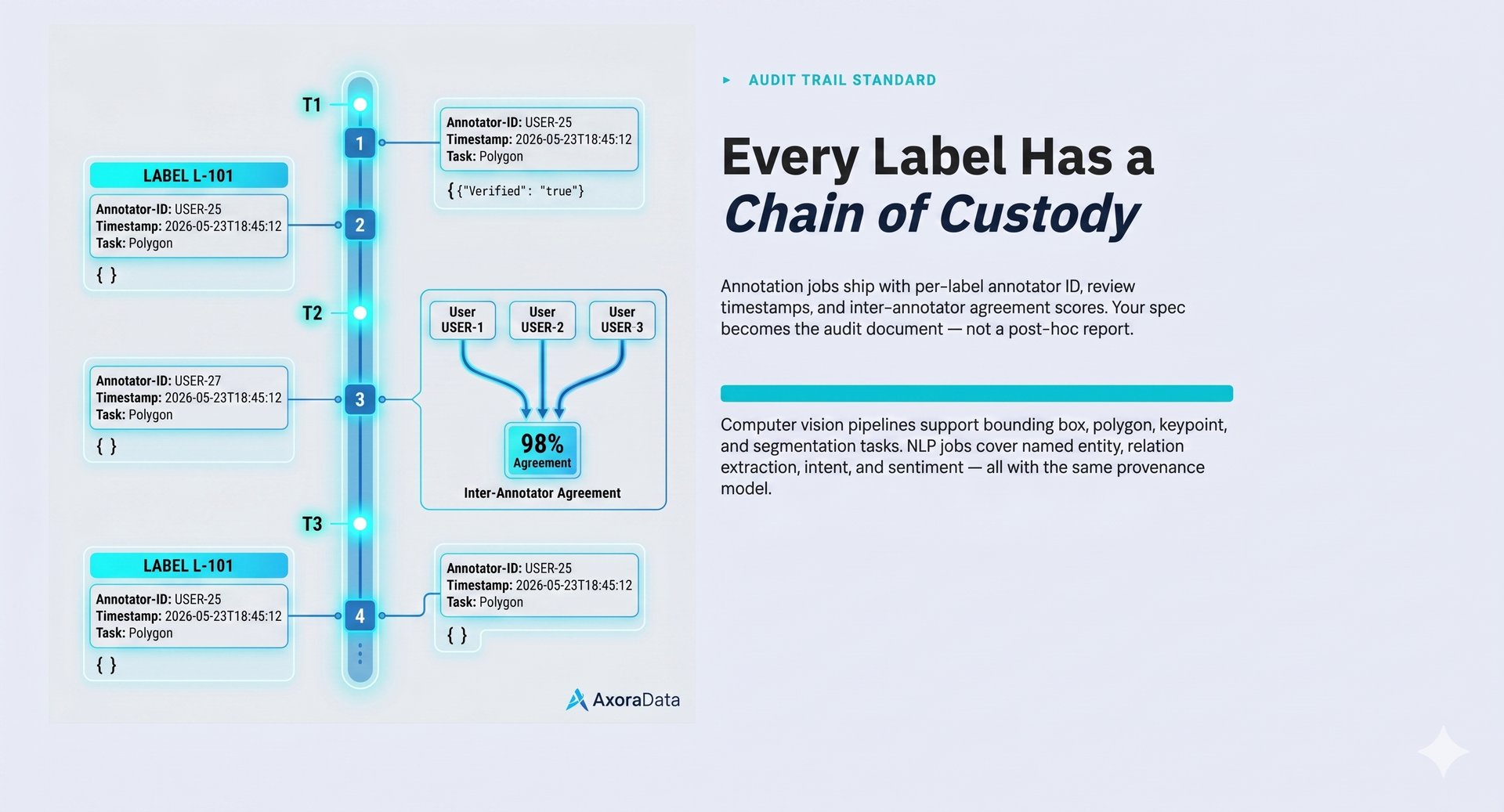
Computer vision and NLP jobs with per-label annotator ID, timestamp, and review chain. Every decision is traceable back to its source for compliance and model debugging.
Contractual accuracy benchmarks scoped per domain — medical, legal, technical. Speaker diarization, custom vocabulary, and timestamped output included as standard.


Recording
High-Fidelity Audio Sourcing
Custom audio collection of scripted and spontaneous speech. Engineered by native speakers across diverse demographics. Delivered with strict acoustic environment controls to eliminate training bias and accelerate precise model iteration
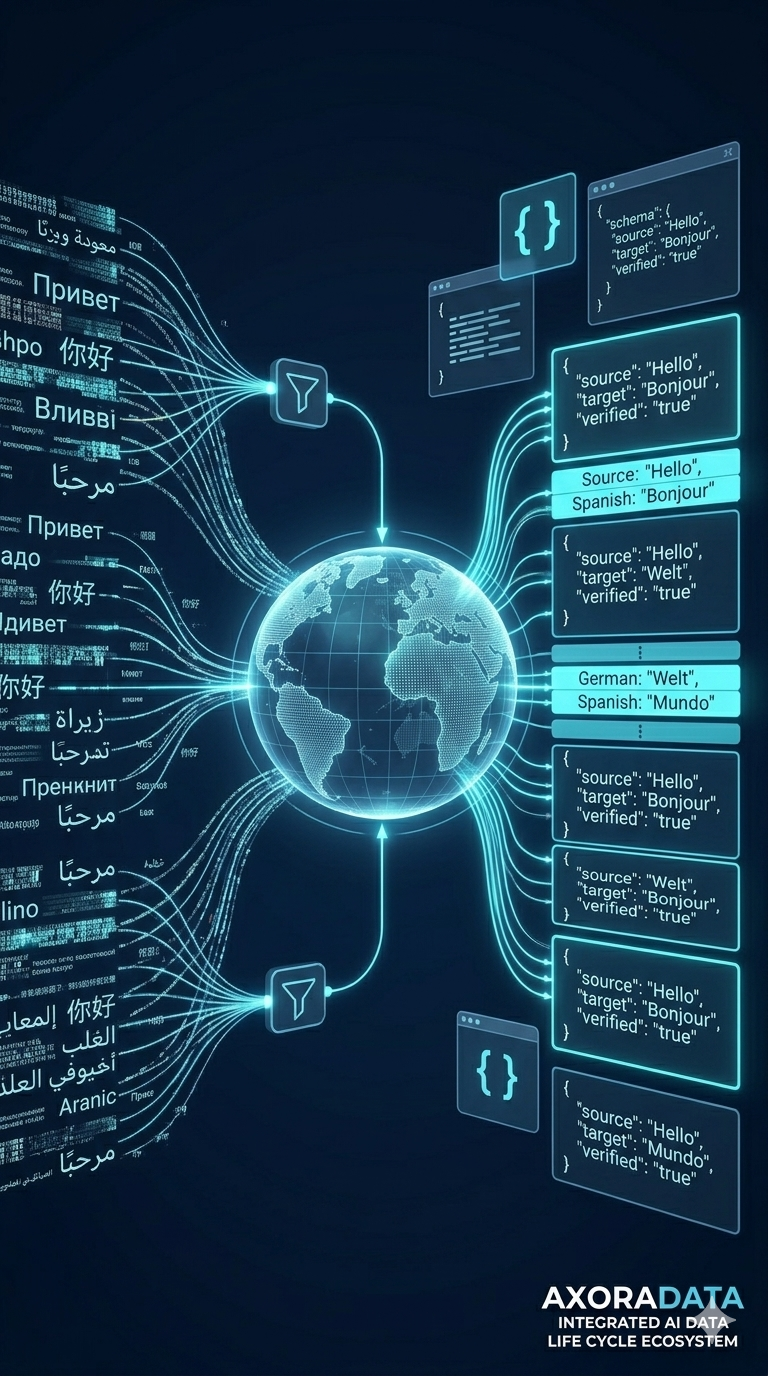



Translation
Custom Data Collection
50+ Languages, Edge Cases Documented
Consent-Managed, Edge-Case Sourcing
Bespoke data collection with documented consent frameworks, sourcing methodology, and edge-case coverage plans. Every dataset ships with a provenance record your legal team can review.
Human-reviewed translation pipelines across 50+ languages. Dialect handling, domain glossaries, and out-of-vocabulary edge cases resolved and logged — not silently dropped.


OCR & DIGITIZATION
Precision Text Extraction
High-accuracy OCR pipelines for complex, unstructured document layouts. Specialized extraction for handwritten and printed texts, governed by strict spatial bounding-box specs.

Know Your Modality. Define Your Threshold.
A technical assessment maps your data type, volume, and accuracy requirements to a concrete delivery spec. Bring your pipeline constraints — we'll work from those.